作者leafwind ()
看板DataScience
标题Re: [请益] Data Engineer门槛问题
时间Wed Mar 28 22:54:51 2018
→ sssh5566: 既然Data Engineer缺的人比较多。。何不多开几个班 03/21 16:49
→ sssh5566: 目前大多是以教如何成为data scientist的课程 03/21 16:50
除了「model 比较潮、清 data 比较脏」这类潜在吸金难易度的差异之外
提供另一个面向做参考
一个原因是业界不清楚人才需求,所以人才雇用错置
资料科学(要讲AI也行)相关领域还不够成熟
成熟到足以让雇主意识到,目前的人力需求是偏向资料工程这一端
https://pbs.twimg.com/media/DHTgw9uXkAQ9MAm.jpg
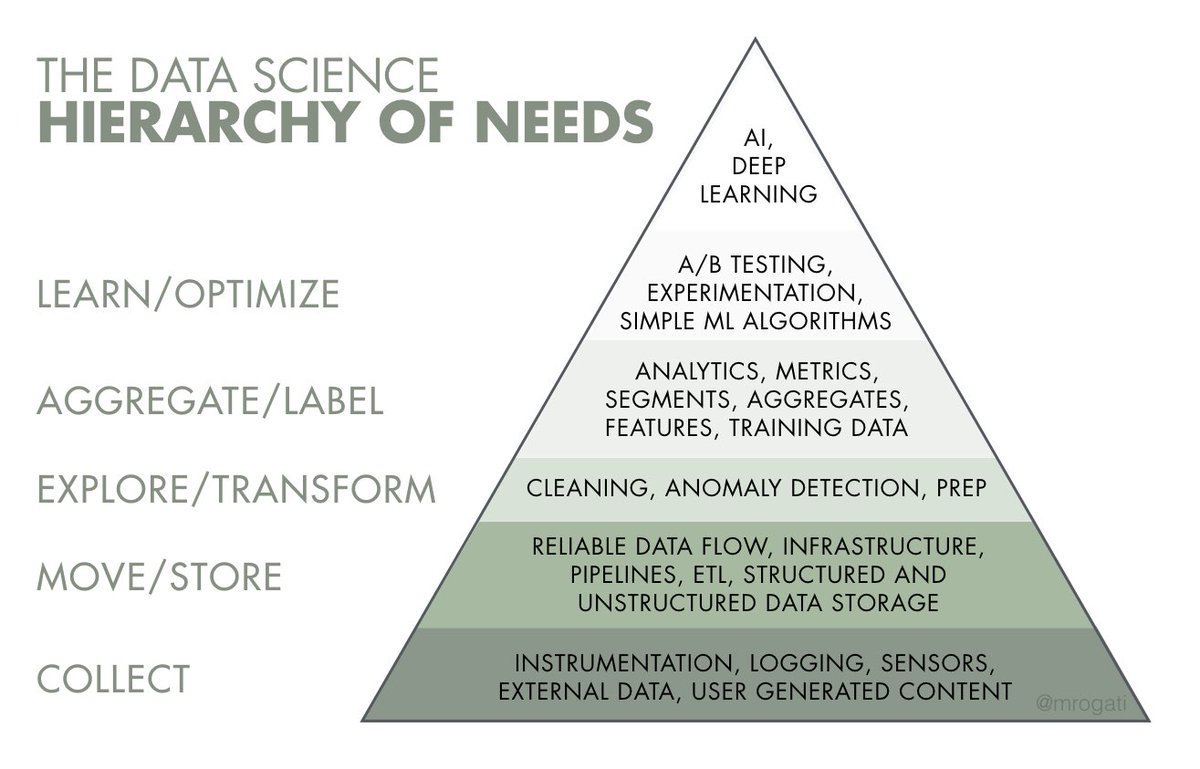
(完整文章参考文末的 AI 需求金字塔)
非常多的雇用错置,发生在各公司里面
比如很常听到的「学了 deep learning 想要建模,结果上班整天都在清资料」
大家都想用魔法做出小当家料理
很少人愿意去摘水果(资料收集)、清洗食材(资料清理)、搬运食材(资料流)、
储存(资料库)、毒物检验(异常资料侦测)、中间产物(预处理)
这些都还只是拿到可以用的食材而已
还有大量反覆的实验跟假设等繁琐步骤要尝试,才可能到最後的建模
甚至有些时候业界用不到复杂的建模,简单的直觉作法即可,因为模型差距没有那麽大
而这些可能还都会被归类在「无聊」的范畴
不只工程师/科学家不想做,雇主可能也没有察觉到重要性
另一个原因是养成困难
学校可能不太教资料工程,这不打紧,以前学校也不太教前端或网页技术
但在资料科学领域,学界与业界都各自还有别的问题,加深了这个严重性
一是(至少台湾)学界把资源大量投注在 deep learning
人才及经费资源多少也排挤到其他更下层的领域(下层=AI 需求金字塔下层)
(虽然这些资源不去做 deep learning 也未必会到资料工程啦..QQ)
再者是即使部分雇主知道资料工程的重要性
但资料工程的技能养成,不像其他领域已经有一套系统性的学习方法能教
几乎都是 on job training 为主
如果只能拿到死的 dataset,即使数量级够大,离要解决真实问题还有很远的一段路要走
借用我之前写的段落
「可惜的是这些经验在学校、学术界极难取得,
如同 Adam Gibson 的访谈中所说,很多东西是只有在业界产品才能学到的,
像是 ETL、软体工程、特定领域资料的知识。并且很遗憾地,也无法速成」
以目前资料被大公司垄断的程度来看
能提供大量真实业务资料的公司,相较於需要的资料工程师缺额,还是不够
(以台湾的软体公司数量来看,那差距就更大了)
幸好这领域也慢慢地比较成熟,有很多框架跟知识被建立起来
预期热潮退了之後,各方也会比较理性,回来检视真正需要的技能是什麽
国外很多文章都已经有了比较系统性的讨论
(上面很多东西也都只是拿人家讲过的来用而已,可以看下面 airbnb 工程师的文章)
所以回到原本的问题
只要 1. 业界发现需求在资料工程端,有更多老板买单
并且 2. 可以在课堂上被某种程度「教学」
或许哪天自学 data engineering 出师也不是不可能吧(?)
===
参考资料们:
1. AI 需求金字塔的概念是从这篇来的
https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007
2. 这篇是 airbnb 的工程师写的文章,非常浅显易懂
A Beginner’s Guide to Data Engineering—Part I
https://medium.com/@rchang/a-beginners-guide-to-data-engineering-part-i-4227c5c457d7
缩:
https://goo.gl/vzDYue
3. 自己的文章,想讲的上面都讲了,有兴趣看其他想法再点吧
https://data.leafwind.tw/build-software-engineering-and-data-culture-before-doing-ai-6e345986f872
缩:
https://goo.gl/kdiir2
--
※ 发信站: 批踢踢实业坊(ptt.cc), 来自: 122.116.34.165
※ 文章网址: https://webptt.com/cn.aspx?n=bbs/DataScience/M.1522248902.A.80B.html
1F:推 Panthalassa: 推好懂 03/28 23:14
2F:推 ranch941: 谢谢分享! 03/28 23:21
3F:→ goldflower: 推个 像之前某个人资朋友说他们找data engineer和 03/28 23:32
4F:→ goldflower: data scientist是1:1 结果到现在都还在清资料 03/28 23:32
5F:→ goldflower: data scientist处於半挂网状态 03/28 23:33
6F:推 woogee: 推,自己在职场上遇到的问题是想要以码农的方式管理 03/29 00:01
7F:→ woogee: 常常都要看git上传了多少Code 03/29 00:02
8F:→ woogee: 但又不可能效果很差甚至某些只是实验性套用的演算法都丢上 03/29 00:03
9F:→ woogee: git管理,然後主管就会觉得好像都没在做事.. 03/29 00:03
10F:推 lucien0410: 推 好文推广 03/29 08:39
11F:推 kokolotl: 老板觉得:资料工程怎麽花这麽多时间,我要的东西呢? 03/29 09:54
12F:推 shaform: 之前也有听某个朋友说他们公司是招 scientist 可是其实 03/29 13:02
13F:→ shaform: 大部分时间做的事比较像 engineer @@! 03/29 13:03
14F:推 kokolotl: 看很多104上面的描述,从DB到模型到视觉化都一个人包 03/29 13:54
15F:推 tay2510: 推这篇 03/30 03:24
16F:推 clang: 推好懂+1 03/30 19:51
17F:推 andrewkgs: 推 03/31 16:06
18F:推 niceallen: 推 感同身受 04/02 23:57
19F:推 taylor0607: 推 05/31 23:55